Artificial intelligence has the potential to revolutionize healthcare, improving patient outcomes, optimizing care delivery, and reducing costs. However, strict regulations intended to protect patients impede the industry’s ability to innovate with AI, limiting the benefits those same patients could experience from the latest technological advancements. Peer-to-peer distributed machine learning techniques can address some of these obstacles, as demonstrated by a proof-of-concept implementation called peer-nnet, developed by myself and Milan Kordic.
The Problem
One of the primary challenges of building AI in healthcare is access to sufficient training data. Without vast training data, it’s difficult to achieve highly accurate and generalizable models that deliver true value. Ideally firms can train on top of a large centralized dataset, but regulations and privacy concerns create several obstacles for healthcare firms to achieve this:
- Data privacy and consent: Healthcare data is subject to strict regulations, such as PIPEDA and other provincial privacy legislation in Canada, and HIPAA in the United States. These regulations impose limitations on how patient data can be collected, used, and shared, making it difficult for healthcare organizations to source adequate data from their own sources.
- Data sharing and collaboration: Healthcare organizations often operate in silos, and sharing data between different institutions can be challenging due to privacy concerns and legal restrictions. This limits the amount of data available for AI applications and can hinder the development of more accurate and effective models.
- Data security and breach risks: Healthcare organizations are responsible for ensuring patient data is secure when stored and transmitted between parties. Implementing AI solutions may require additional security measures, such as encryption and secure data transfer protocols, which can be resource-intensive and increase the risk of breaches or unauthorized access.
As a result, healthcare companies might find it difficult to gather sufficient data and encounter significant obstacles when attempting to source training data with other healthcare organizations.
Federated Machine Learning as a Solution
Federated learning (FL) is a technique that allows multiple parties to collaboratively train a shared machine learning model on their local data without sharing the underlying data itself. This collaborative approach allows healthcare companies to pool their resources and gain access to a much larger, diverse dataset, enhancing the quality of the machine learning models for everyone.
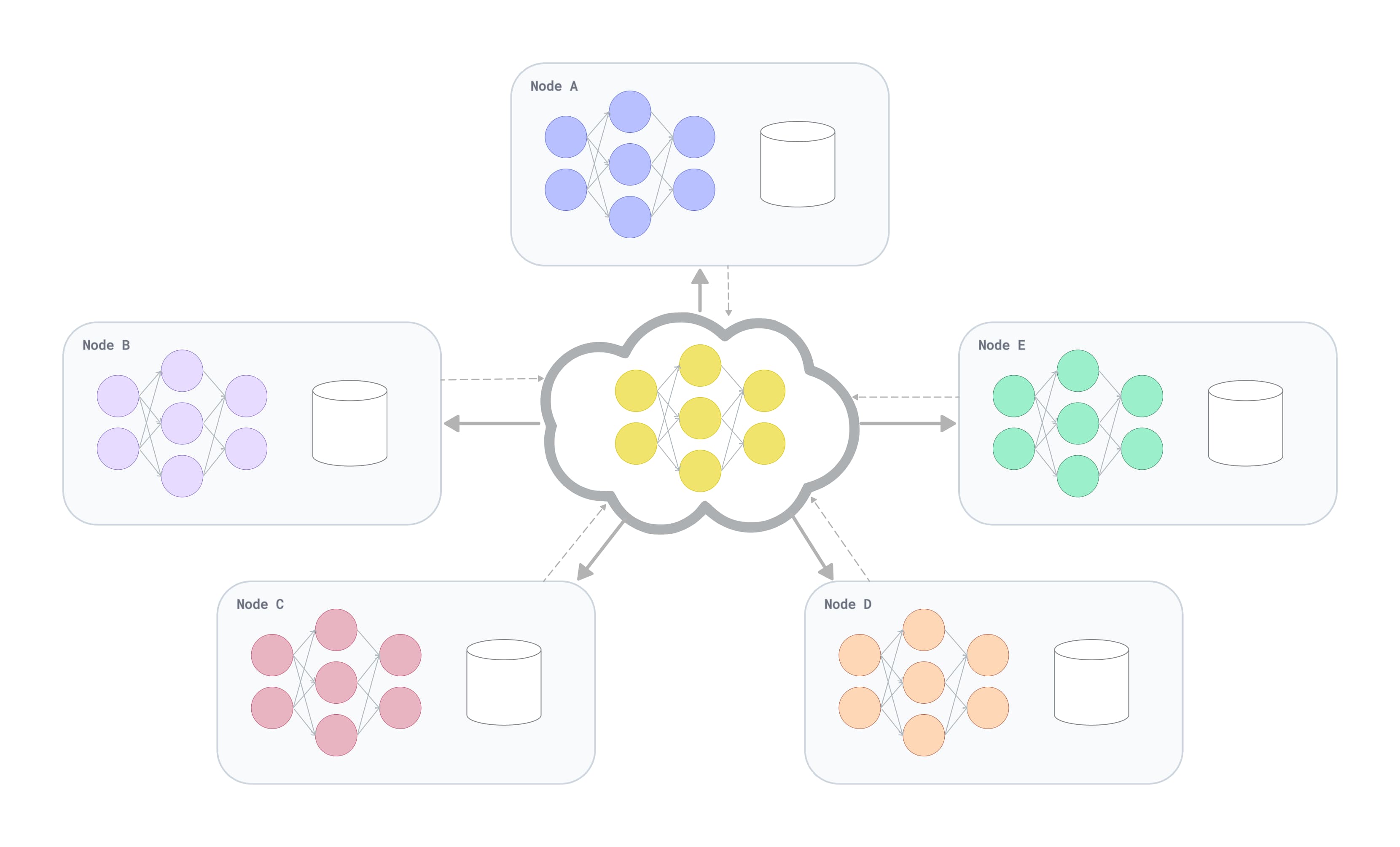
While most federated architectures assume a central authority to orchestrate the activity, a decentralized architecture employing peer-to-peer technology can also be used. This architecture uniquely addresses several pressures that face healthcare firms:
- Data privacy: In a distributed federated learning architecture, raw patient data remains local to each organization, eliminating the need to share sensitive data with other parties. This helps maintain data privacy and ensure regulatory compliance.
- Data security: Since sensitive patient data is not transmitted over the network or stored in a central location, there is minimal risk of data breaches or unauthorized access.
- Collaborative learning: A distributed federated learning approach enables healthcare organizations to collaboratively train machine learning models on a larger and more diverse dataset, without sharing the actual data. This can lead to improved model accuracy and generalizability.
- Autonomy and flexibility: Without a central authority, healthcare organizations can maintain autonomy over their data and processes. They can choose their own machine learning hyper parameters, data preprocessing techniques, and learning schedules, allowing them to adapt the federated learning process to their needs and constraints.
- Fault tolerance: The architecture prevents single point failures because model weight updates are exchanged only between the interconnected peers. There is no central authority required to orchestrate the training process - significantly minimizing the risk of network failure.
Introducing peer-nnet
peer-nnet is a proof-of-concept peer-to-peer application demonstrating the potential of decentralized FL in healthcare. It provides the infrastructure for federated learning over a network of peers without a centralized learning process. The only data shared between participants are the model weights used to train their local models. The research paper “BrainTorrent: A Peer-to-Peer Environment for Decentralized Federated Learning” inspired the general learning algorithm used in the proof-of-concept. The researchers found that this approach “does not only outperform the traditional server-based one but reaches a similar performance to a model trained on pooled data.”
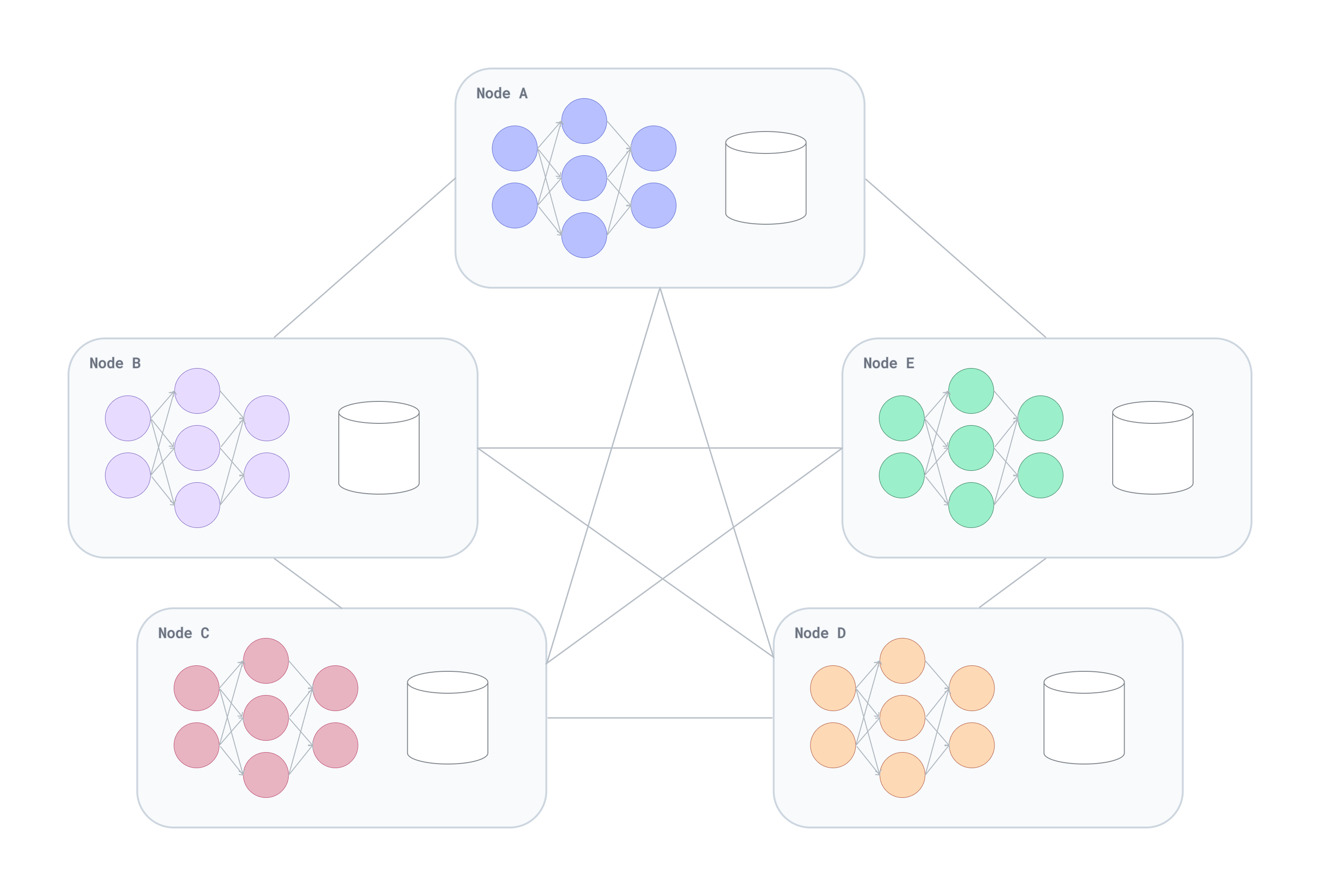
Architecture
peer-nnet’s architecture is designed to facilitate secure and decentralized machine learning across a network of peers.
Each node (peer) within network consists of a networking application, machine learning manager, and a shared filesystem.
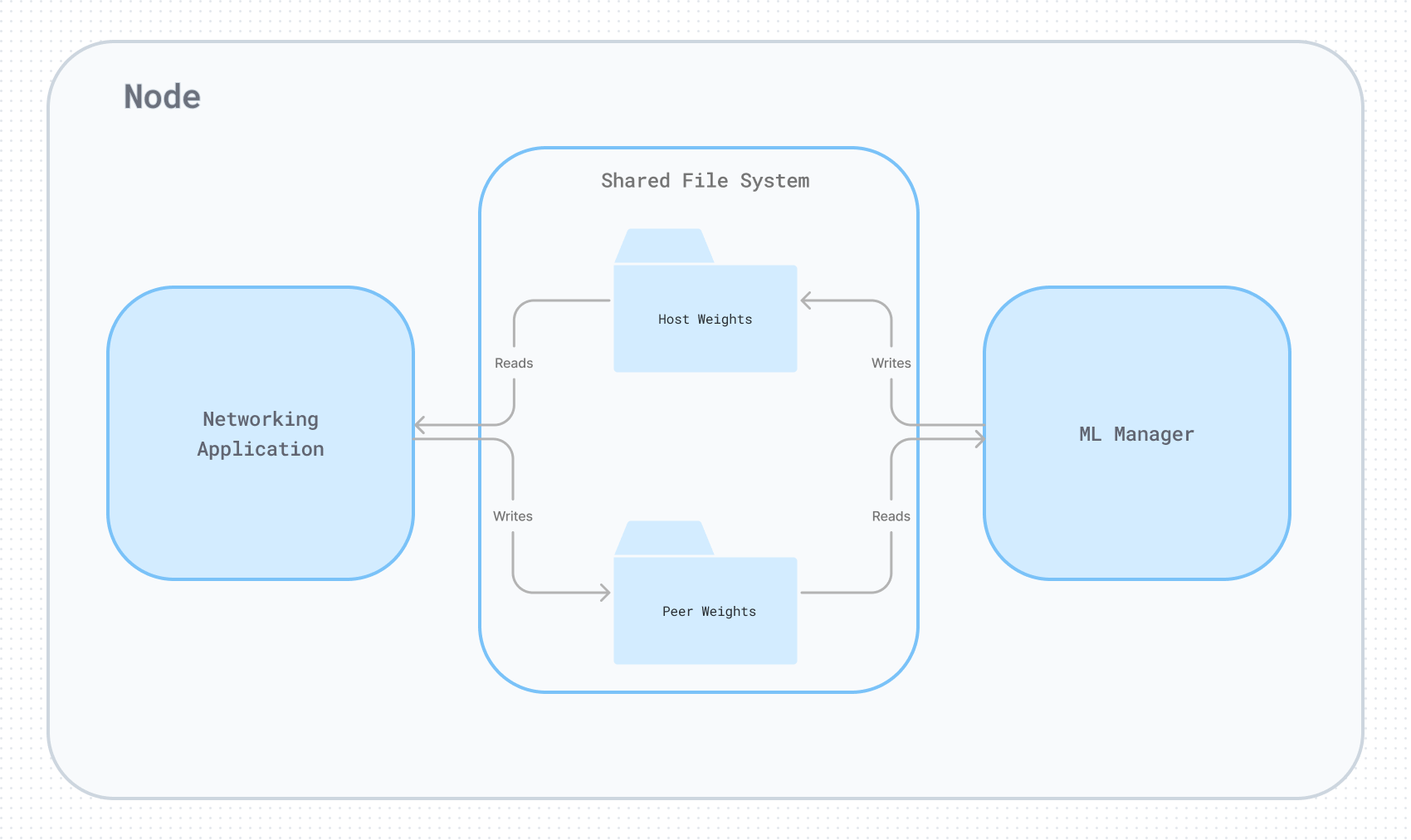
- Networking application: Built with Go and libp2p, the networking application handles peer discovery, connection management, secure communication channels, model weight exchange, error recovery, and conflict resolution. Libp2p is a modular network stack that enables the development of peer-to-peer applications, providing essential features such as peer discovery, connection management, and secure communication channels.
- Machine learning manager: The machine learning process trains an ML model on locally available data and periodically saves updated model weights to a shared filesystem. The process incorporates an aggregation mechanism that combines the weights received from various peers, so each re-training benefits from the collective knowledge of all participating nodes in the network. Periodically, this process saves the updated model weights to a file in a shared filesystem to be shared by the networking application (1).
- Shared filesystem: The shared filesystem is the primary method of communication between the networking application and the machine learning process. The networking application retrieves the latest model weights saved by the machine learning process and shares them with connected peers. Conversely, the networking application writes received model weight updates from other peers to the shared filesystem, allowing the machine learning process to load and incorporate those updates into its training.
- Security and privacy: Communication between nodes is encrypted using secure channels provided by the libp2p library. Additionally, sharing model weights, rather than raw patient data, helps maintain patient privacy and comply with healthcare regulations.
Limitations
| Limitation | Description | Impact of Risk |
|---|---|---|
| Model compatibility | All participating organizations must use the same machine learning model architecture. Each organization may have its own unique patient population, data characteristics, and desired model performance objectives, which might require different model architectures. | High |
| Model alignment | Models trained on different patient populations may introduce biases, requiring alignment and bias mitigation before combining weights from other participants. | Medium |
Conclusion
Decentralized federated learning holds significant promise for the healthcare sector by enabling organizations to collaborate and train AI models while respecting patient privacy and regulatory constraints. Peer-nnet serves as a proof-of-concept for this approach. While some limitations and challenges need to be addressed when adopting this architecture, this approach offers a viable path to harness the power of AI to drive innovation and improve patient outcomes.
I acknowledge that the technical solution is just one piece of the puzzle in the broader initiative to successfully adopt and deploy ML applications within healthcare. I’m eager to learn more about the various challenges in this space and welcome any feedback on this post and insights on the space. Thanks for reading!